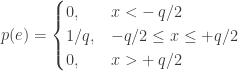Before embarking on a new design, it is important to plan ahead and create a strategy for verifying the correct operation of that design. In the case of designing digital circuitry in a hardware description language (HDL), it is best to begin with the testbench before creating the actual design itself. In this way, as the design evolves, the testbench can be continuously modified to actively verify the incremental changes as they occur.
When designing a testbench, file input/output can be an extremely useful feature in order to read-in stimulus data from a file, and write-out results to another file. This allows one to create stimulus and verify correctness of results outside the actual language domain used for designing the block. For example, when designing a DSP system, it is common to use a high-level modeling tool such as Matlab to create and model the system. When a particular portion of the datapath is implemented in RTL, the stimulus at the input and the expected data at the output can all be written out directly from Matlab. These files can then be fed to the event-driven HDL simulation environment of the block and testbench in order to ensure direct equivalence between the two embodiments of the design.
For example, the following Matlab commands can write out the elements of a vector Vstim as single integers on each line in the text file named “teststim.txt”:
% create the vector of integers
Vstim = [5, -3, 19, 7, -13, 10];
% open the file in 'write' mode
FID = fopen('teststim.txt','w');
% write the vector to the file, one element per line
fprintf(FID,'%d\n',Vstim)
% close the file
fclose(FID)
The file “teststim.txt” should now contain the following:
5
-3
19
7
-13
10
Reading and writing files in VHDL is a fairly straight-forward process, but some details need to be settled before proceeding. There are multiple approaches to the read and write flow in a testbench: all-at-once, just-in-time, or some mixture of both. This decision can have an effect on simulation time and size, and also depends on the amount of data involved at each end.
For example, one approach might be to read-in the entire stimulus file before presenting each element to the device under test (DUT) on a clock-cycle to clock-cycle basis. Another approach might be to read-in only what is required for each cycle and waiting until the next element is actually required. Similarly at the output side, data can either be written out as it is produced by the DUT, or it can be saved until the simulation is complete, and then written out all at once. The following is a description of an example VHDL testbench which performs file I/O. It is missing a DUT, but it illustrates file I/O in VHDL.
The first thing to be declared is the testbench entity. Since the testbench is the top-level module, the entity declaration is empty. This is followed by library declarations and the definition of the testbench architecture. The internal constants and signals are described within the code comments:
-- entity declaration for testbench named "fileio"
entity fileio is
end fileio;
-- library declarations
library STD, IEEE;
-- needed for the write and read calls
use STD.textio.all;
-- needed for std_logic data types
use IEEE.std_logic_1164.all;
-- needed for calls to WRITE(LINE, std_logic)
use IEEE.std_logic_textio.all;
-- needed for calls to CONV_STD_LOGIC_VECTOR
use IEEE.std_logic_arith.all;
-- definition of architecture "BEH" for testbench "fileio"
architecture BEH of fileio is
constant CLK_PERIOD : time := 5 ns; -- period of system clock
constant DATA_WIDTH : integer := 6; -- width of data vector
-- definitions of input and output file names and access types
file INPUT_FILE : TEXT open READ_MODE is "teststim.txt";
file OUTPUT_FILE : TEXT open WRITE_MODE is "testout.txt";
signal clk_sys : std_logic := '0'; -- system clock
signal eof : std_logic := '0'; -- flag end of file
signal read_en : std_logic := '0'; -- enable reading
signal write_en : std_logic := '0'; -- enable writing
-- data vector for representing stimulus integers
signal current_data_vec : std_logic_vector(DATA_WIDTH-1 downto 0)
:= (others=>'0');
begin -- begin body of architecture BEH
-- [ THIS IS WHERE ALL PROCESSES GO, AS DEFINED BELOW ]
end BEH; -- end body of architecture BEH
The system clock is defined in order to provide a cyclic reference point for all operations, including reading and writing data. There is a constant declaration for the clock period (arbitrarily defined as 5 ns in this example). The following VHDL line defines the system clock with a perfect 50% duty-cycle:
-- create the system CLOCK
clk_sys <= not clk_sys after CLK_PERIOD/2;
The main control process is where the testbench is controlled, and in this example, the process lacks a sensitivity list. A process without a sensitivity list simply executes code sequentially and repeats indefinitely (until the simulation is terminated). In the case of this example, the simulation is terminated using a “fake” assertion failure, in order to allow the testbench to work on arbitrarily-long stimulus files.
-- MAIN CONTROL process
main_control:
process
begin
-- wait until the next rising clock edge
wait until clk_sys'event and clk_sys='1';
read_en <= '1'; -- enable reading
-- delay writing to the output file by one clock cycle
wait for CLK_PERIOD;
write_en <= '1'; -- enable writing
-- wait for the eof flag to go high
wait until (eof='1');
wait for CLK_PERIOD;
-- close both files
file_close(INPUT_FILE);
file_close(OUTPUT_FILE);
-- terminate the simulation
assert false
report "INFO: this is used to terminate the simulation"
severity failure;
end process main_control;
The read process is sensitive only to the system clock, responds on every rising edge of the system clock and continues to read while reading is enabled. This process keep reading until end-of-file is reached. Reading is enabled through the “read_en” signal, and end-of-file is indicated through the “eof” signal. Data is converted to a vector so the DUT can process the digital representation of the data.
-- READ FILE process
read_from_file:
process (clk_sys) is
variable tmp_line : line;
variable tmp_int : integer;
begin
if (clk_sys'event and clk_sys='1' and read_en='1'
and eof='0') then
if endfile(input_file) then
-- place the status string into a line
write(tmp_line, string'("INFO: reached end of file"));
-- write the line to the output
writeline(output, tmp_line);
-- update the flag
eof <= '1';
else
-- read the next line in the file
readline(INPUT_FILE, tmp_line);
-- parse the line and convert data to integer
read(tmp_line, tmp_int);
-- convert the integer to vector and assign to a signal
current_data_vec <=
CONV_STD_LOGIC_VECTOR(tmp_int,DATA_WIDTH);
-- maintain the flag
eof <= '0';
end if;
end if;
end process read_from_file;
The write process is sensitive only to the system clock, responds on every rising edge of the system clock and continues writing until one clock cycle after the end-of-file is reached in the stimulus file. This single-cycle delay at the end is specified in the main control process, and can be adjusted according to the desired latency through the DUT.
-- WRITE FILE process
write_to_file:
process (clk_sys) is
variable tmp_line : line;
begin
if (clk_sys'event and clk_sys='1' and write_en='1'
and eof='0') then
write(tmp_line, current_data_vec);
writeline(OUTPUT_FILE, tmp_line);
end if;
end process write_to_file;
The above testbench can be easily be compiled and simulated using GHDL (as outlined in this post) using the following shell script:
# Compile the vhdl file
wine ghdl.exe -a --ieee=synopsys fileio.vhd
# Elaborate the testbench
wine ghdl.exe -e --ieee=synopsys fileio
# Simulate the testbench
wine ghdl.exe -r --ieee=synopsys fileio
When the simulation is run, the shell output should look something like this:
INFO: reached end of file
fileio.vhd:52:9:@42500ps:(assertion failure): INFO: this is used to terminate the simulation
C:\Program Files\Ghdl\Bin\ghdl.exe:error: assertion failed
C:\Program Files\Ghdl\Bin\ghdl.exe:error: simulation failed
The output file “testout.txt” should contain the following lines of signed integer converted to a two’s complement representation of the contents of “teststim.txt”.
000101
111101
010011
000111
110011
001010
In this example the digital data is being written directly to the output file in order to illustrate file I/O. In reality, it would be more convenient to convert the output of the DUT back to a signed integer before writing to the output file, thereby allowing Matlab to easily process and verify the output.
This type of testbench is just the first step to block-level design. The next step would be to actually design and instantiate the block (or DUT) into the testbench, taking care of any interface requirements. Throughout the design process, the testbench will have to keep up with the signalling needs of the block to be tested, as the needs arise.
Copyright © 2010-2012 Waqas Akram. All Rights Reserved.
Read Full Post »
![\delta[n] = \begin{cases} 1, & n = 0 \\ 0, & otherwise \end{cases}](https://s0.wp.com/latex.php?latex=%5Cdelta%5Bn%5D+%3D+%5Cbegin%7Bcases%7D++++++++++++++++1%2C+%26+n+%3D+0+%5C%5C++++++++++%09+++++0%2C+%26+otherwise+++++%5Cend%7Bcases%7D+++&bg=ffffff&fg=333333&s=0&c=20201002)
![y[n] = x[n] + y[n-1] + y[n-2]](https://s0.wp.com/latex.php?latex=y%5Bn%5D+%3D+x%5Bn%5D+%2B+y%5Bn-1%5D+%2B+y%5Bn-2%5D++&bg=ffffff&fg=333333&s=0&c=20201002)